LakeFormation と GlueStudio で S3 を使った簡単データレイク環境構築
LakeFormation と GlueStudio を使ってデータレイク環境を構築する
データ配置先の作成
データレイク環境を作り、そこに溜め込みたいデータ配置環境を用意する
今回はデータ配置先としてS3を使う
- インプットデータ配置先:S3(dp-datalake-dev)
- 取り込みデータベース :S3(dp-output-dev)
LakeFormationの設定
作成したデータレイク環境へのアクセス制御として IAM があるが、IAM ではサービス単位でしかアクセス制御が行えないため
テーブルやデータベース単位での細かなアクセス制御や、ダッシュボードを通して Glue、GlueStudioで作成した各種環境を一覧的に見ることが出来る
IAM上でサービスに対してFullの権限が与えられていてもLakeFormation上で権限が無いと操作できないように制御可能
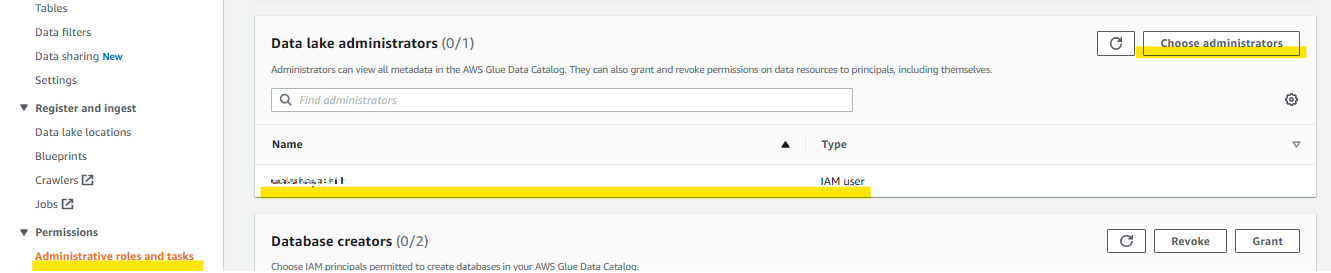
LakeFormation管理者権限の設定
LakeFormation上の管理者権限、データベースの作成削除からあらゆる権限操作が可能となる

CatalogDBの作成
作成したS3のデータ配置先をカタログDBとして登録
▼インプットデータDB
▼取り込み後データDB
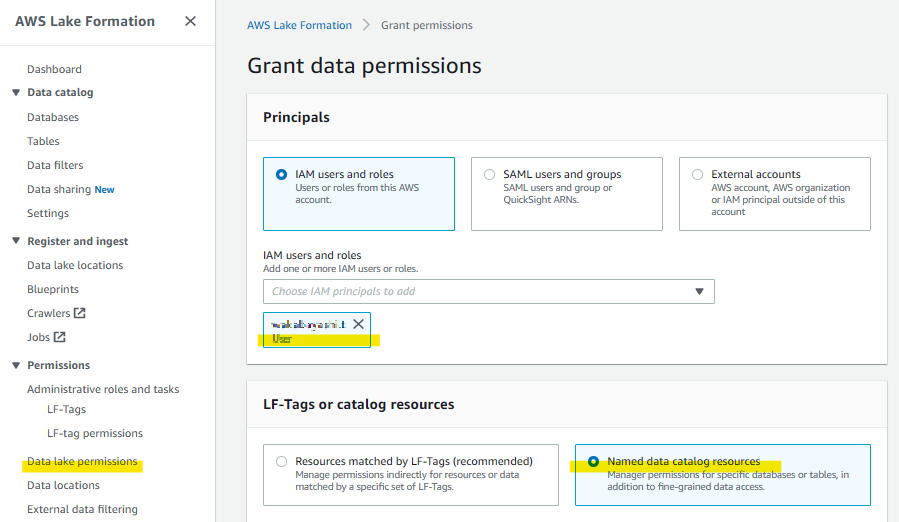
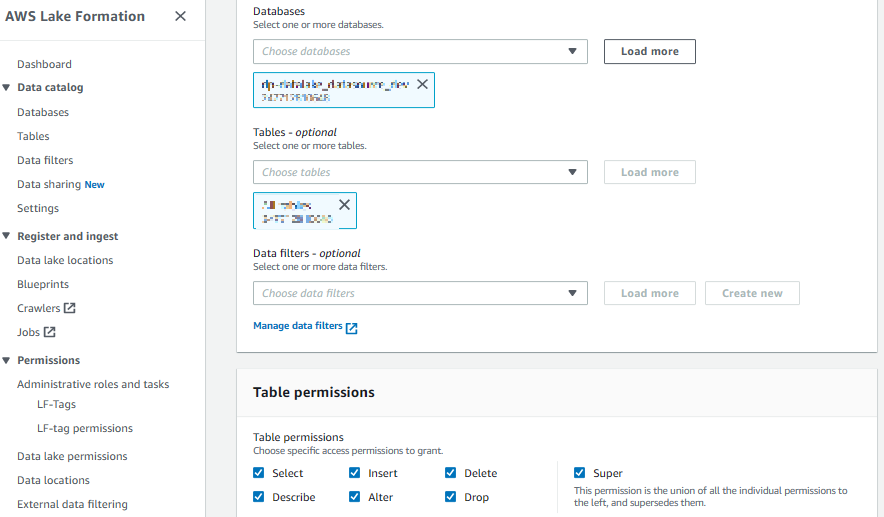
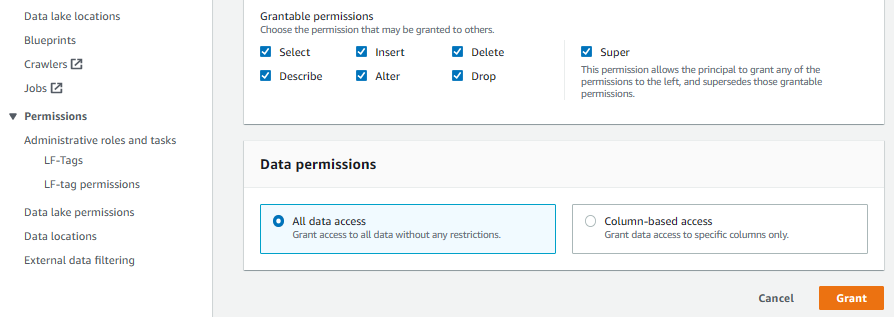
カタログデータベースに対する権限設定
カタログデータベースに対してどの IAM、ロールがどのような権限でアクセス可能か定義する
IAMアクセス制御の解除
IAMによるデータベース等へのアクセスコントロールを解除
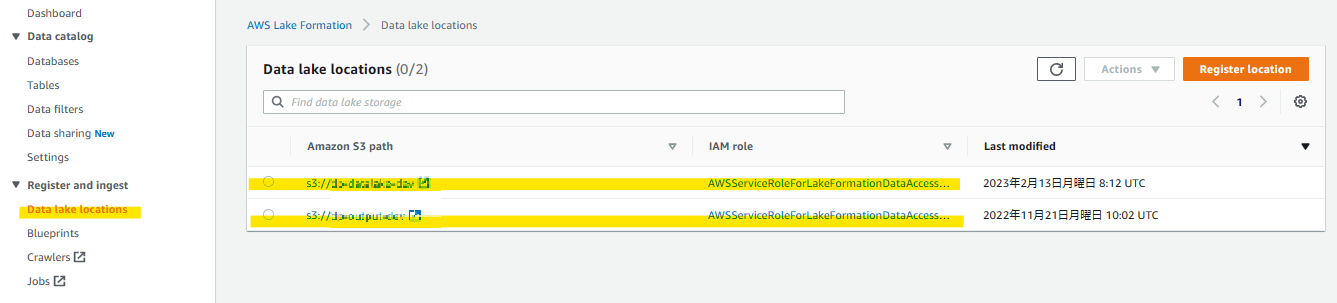
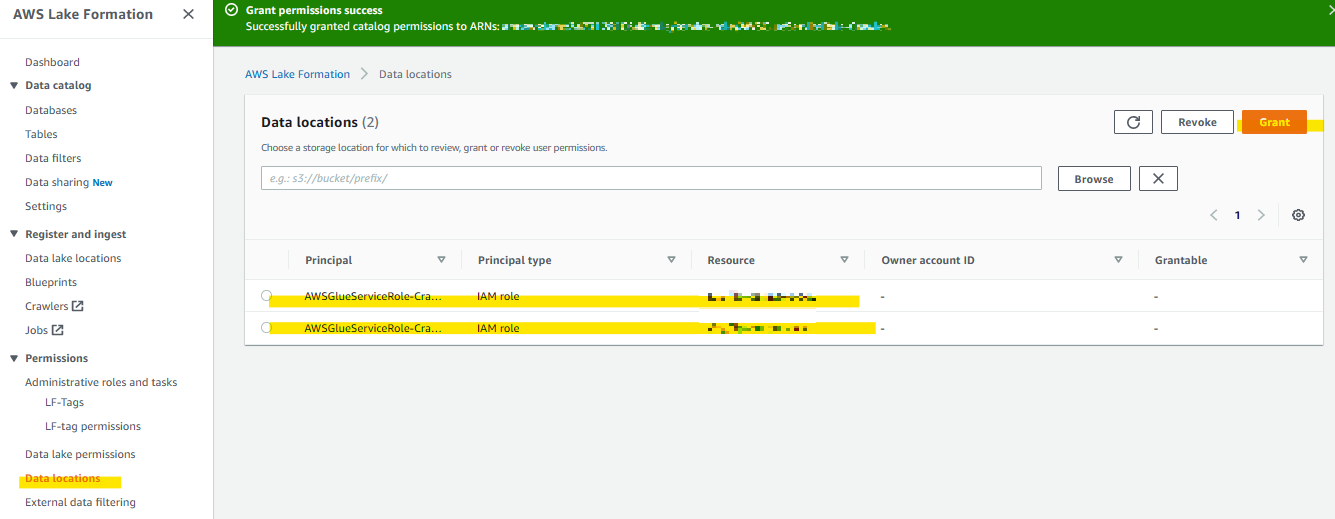
データレイクロケーションの登録
データ配置先となるS3を登録することで「AWSServiceRoleForLakeFormationDataAccess」ロールに対して適切な権限が設定される
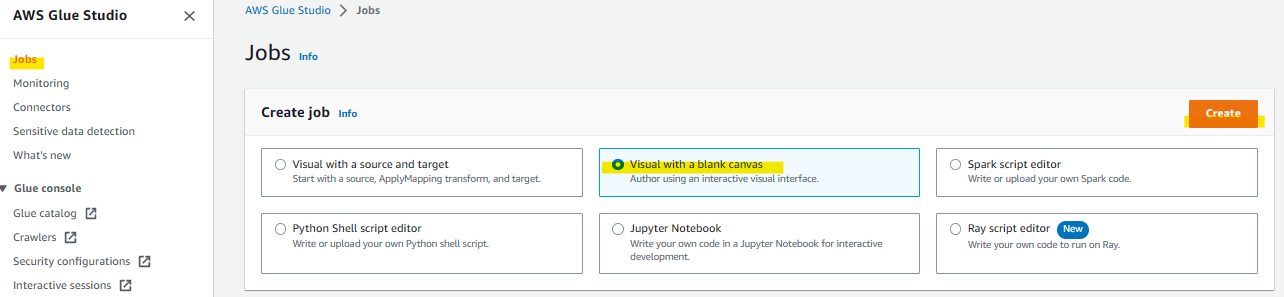
GlueStudioでのETL設定
集約したデータファイルをETLで整形、フィルターを行い蓄積用データベースに集約するためのETLジョブを作成する
ここでは視覚的にわかりやすい「Visual with a blank canvas」でジョブを作成する
事前にインプット用S3に必要なデータを配置しておく
ETLジョブの作成
インプット用S3の特定のディレクトリ配下に配置されたCSVファイルを取り込むためのジョブを作成する
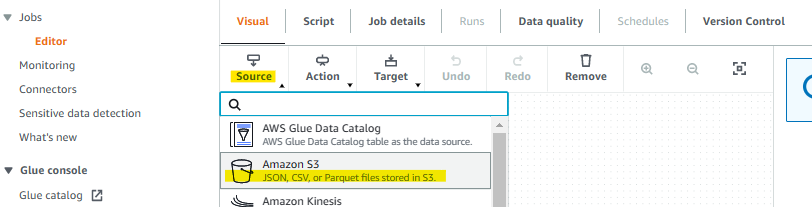
取り込むデータ形式に合わせて定義
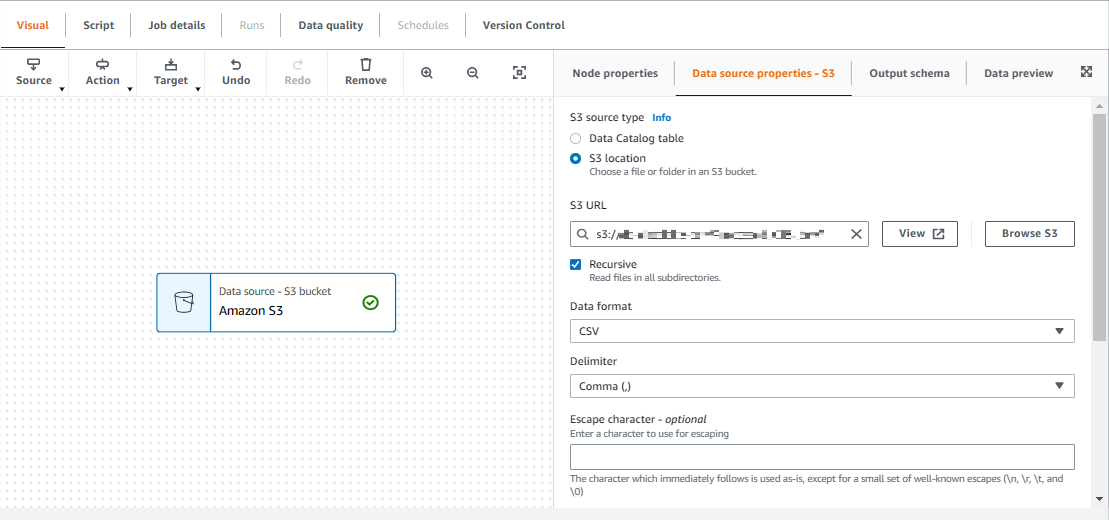
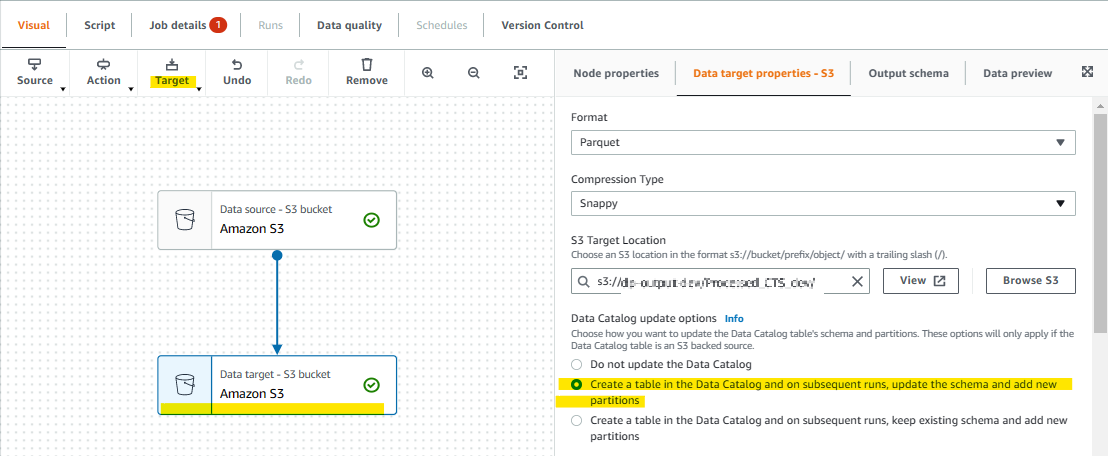
出力先、データレイクとして蓄積するデータベースを指定
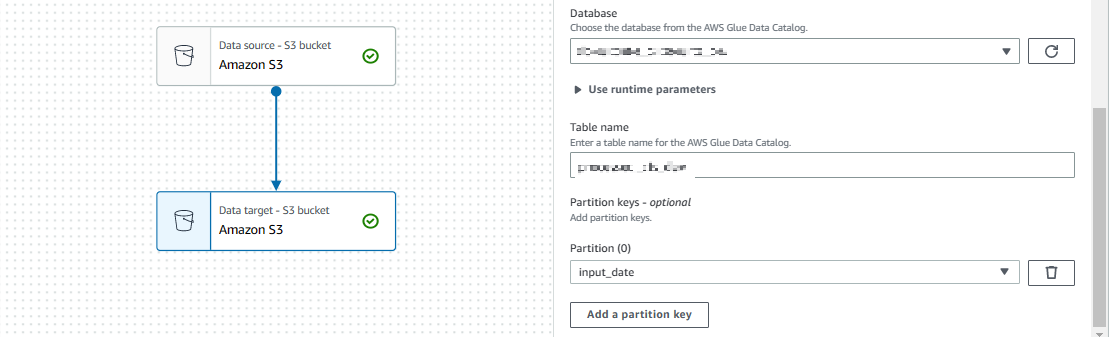
この場合出力先のS3をデータベースとして利用し、Athena でクエリ操作できるようにパーティションの設定も行える
実行ロールの設定
Glueジョブのジョブ名、実行ロールを指定
ロールはデフォルトのものを利用
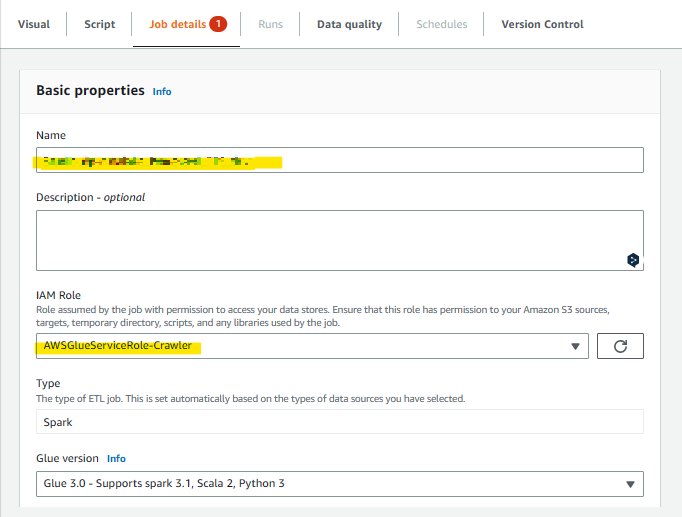
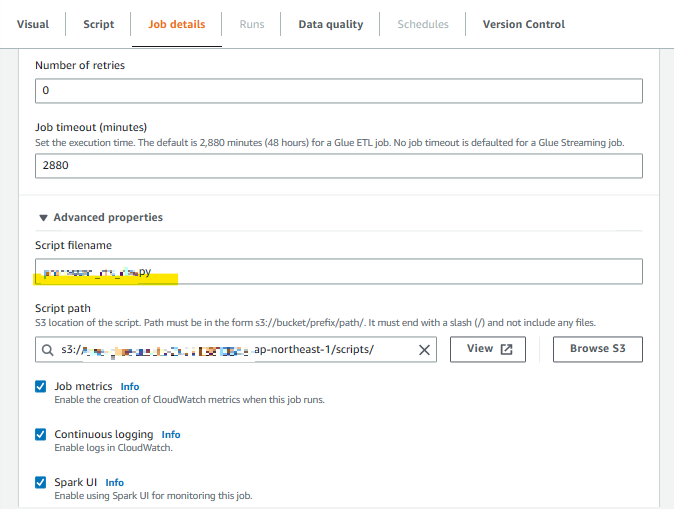
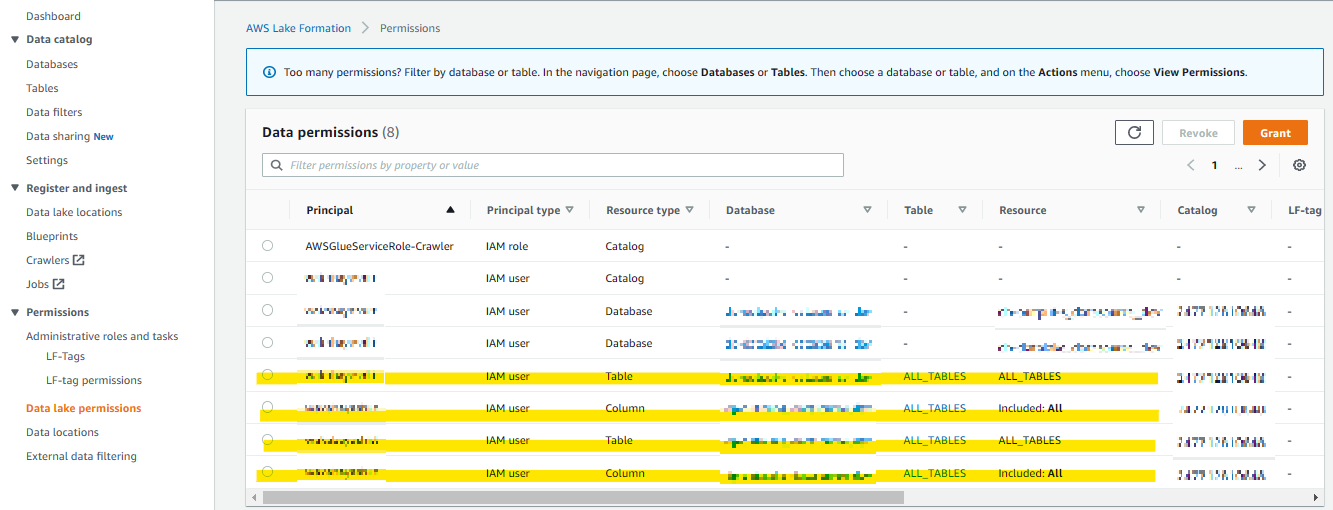
設定したロールに対して LakeFromation上での権限も付与する
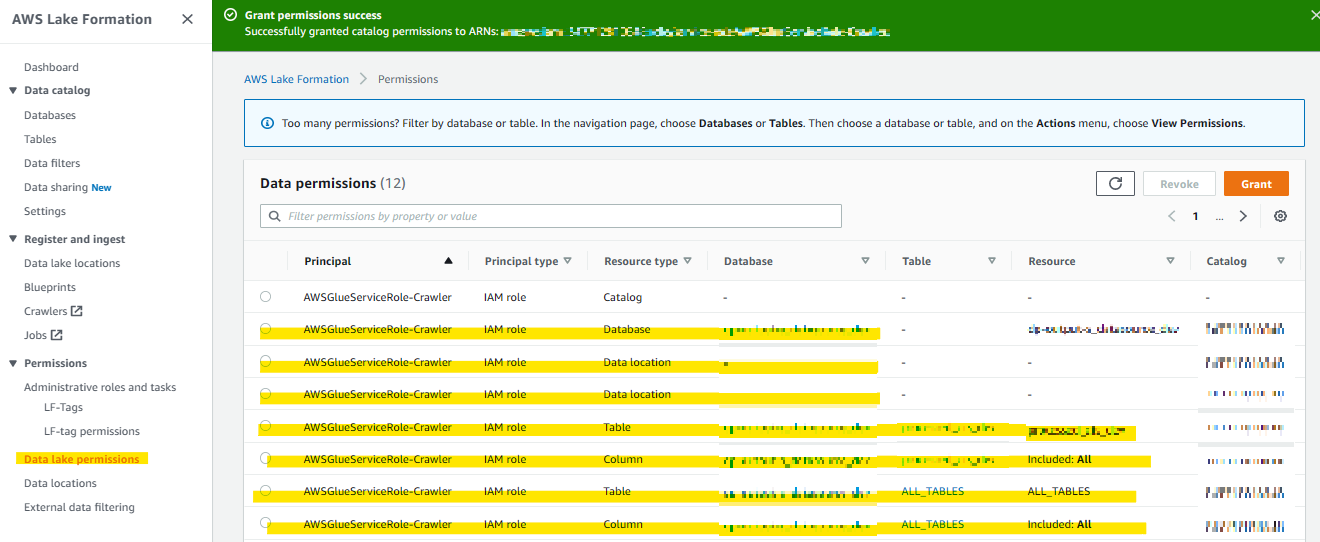
一回ではロールに対して database 権限がつかないため all table 権限と2回実行する
ジョブの実行
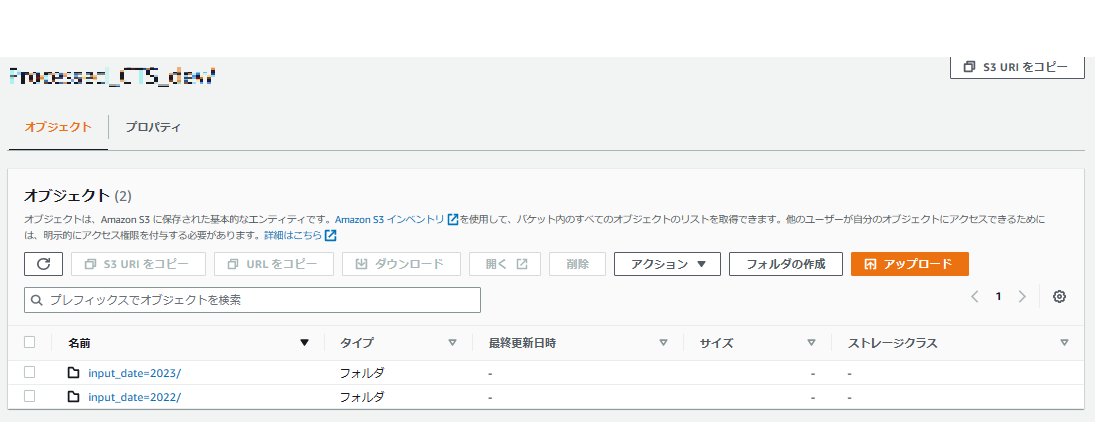
Glue Studio のジョブ画面から作成したジョブを実行すると自動で S3 にパーティション毎にデータが配置され
LakeFormation上にもテーブルが作成され、データの中身について Athena で確認できる
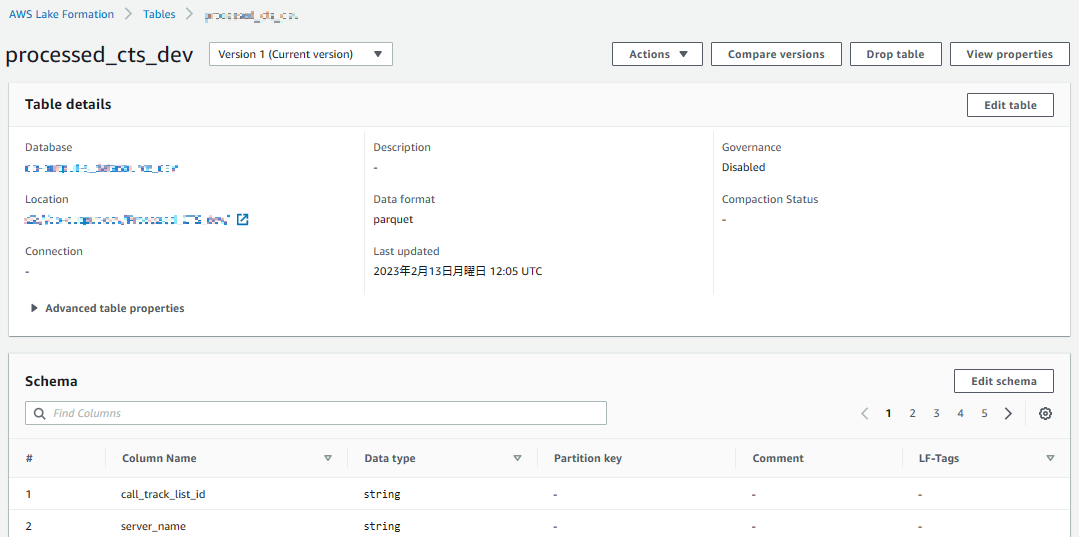
ETLによるデータの加工
例)特定のカラムデータを timestamp 型に修正し、新規カラムにコピーする
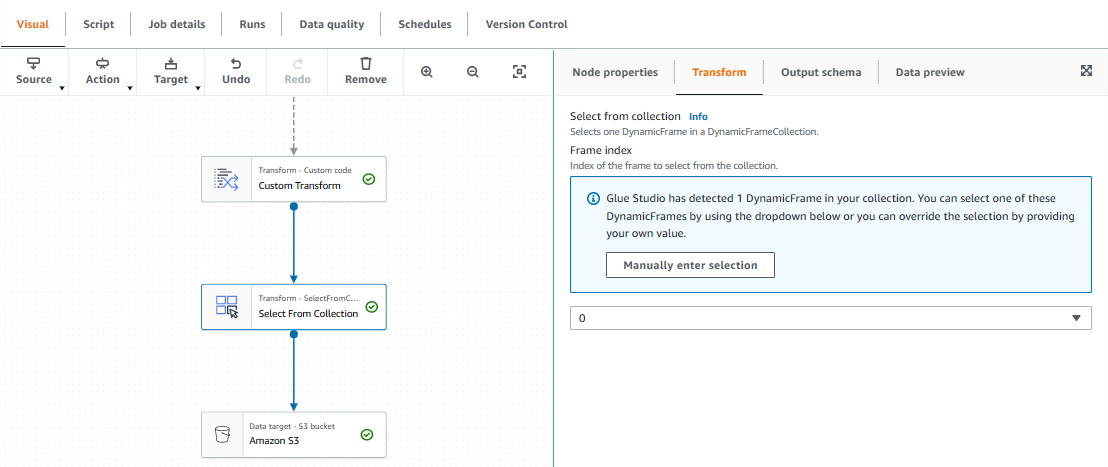
基本の処理に加え Transform Action を追加し、Pyspark スクリプトを記述できる
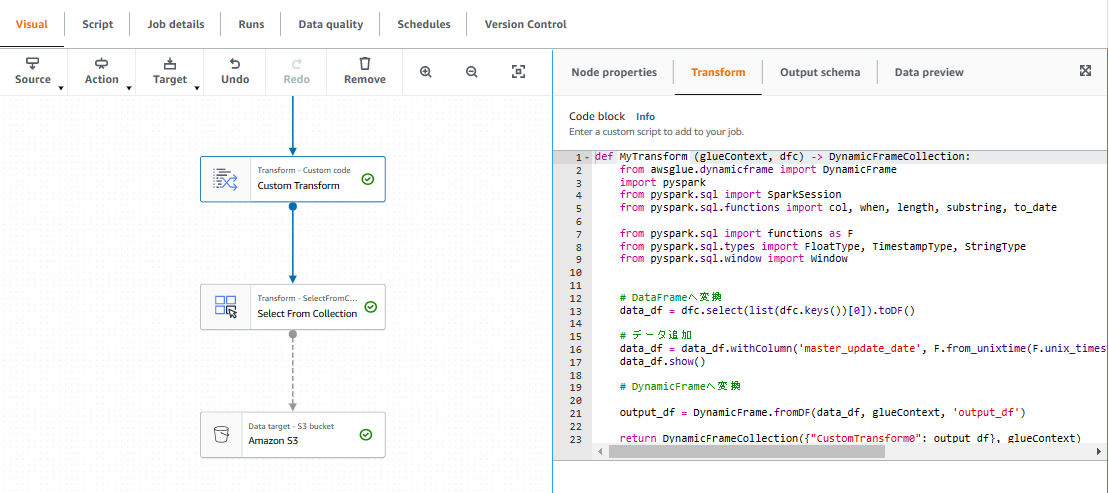
from awsglue.dynamicframe import DynamicFrame
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, length, substring, to_date
from pyspark.sql import functions as F
from pyspark.sql.types import FloatType, TimestampType, StringType
from pyspark.sql.window import Window
# DataFrameへ変換
data_df = dfc.select(list(dfc.keys())[0]).toDF()
# データ追加
data_df = data_df.withColumn('master_update_date', F.from_unixtime(F.unix_timestamp('update_date','yyyy/MM/dd HH:mm:ss')).cast('timestamp'))
data_df.show()
# DynamicFrameへ変換
output_df = DynamicFrame.fromDF(data_df, glueContext, 'output_df')
return DynamicFrameCollection({"CustomTransform0": output_df}, glueContext)
ここでは特定のカラムを timestamp 形式に変換し 新規カラムを追加してデータをコピーしている
カラムの追加は Outputschema から Edit で Add root culumm から追加する
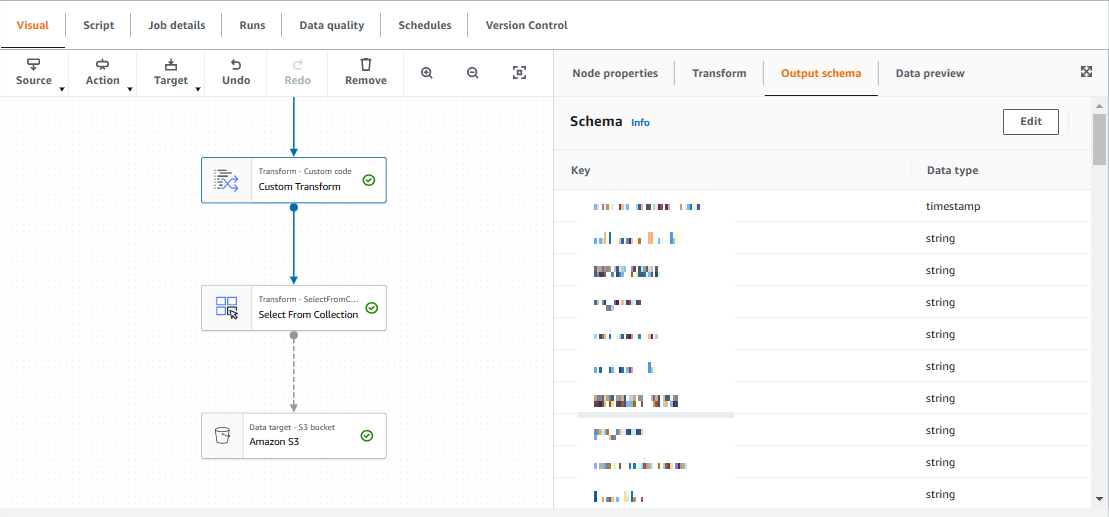
スクリプトにて変更を加えたデータ構造を DynamicFrameCollection として Glue に返し
Transform Select From Collection にて全てをデータとして受け取り 出力先のS3に渡している